Ensemble Methods - Part 1#
Recap CART - Classification and regression trees#
CART (Classification and Regression Tree)#
General:
CART uses a greedy method: at each step it picks the split that looks best right now, not the best possible split overall.
The split function chooses best feature and best value to split on.
Cost functions:
Regression \(\rightarrow J(b)=\frac{1}{n}\sum_{i=1}^{n}{(y_{i}-\hat{y_{i}})^2}\) (MSE)
Classification \(\rightarrow I_{G}(p)= 1-\sum_{i=1}^{J}\,p_{i}^{2}\) (Gini impurity)
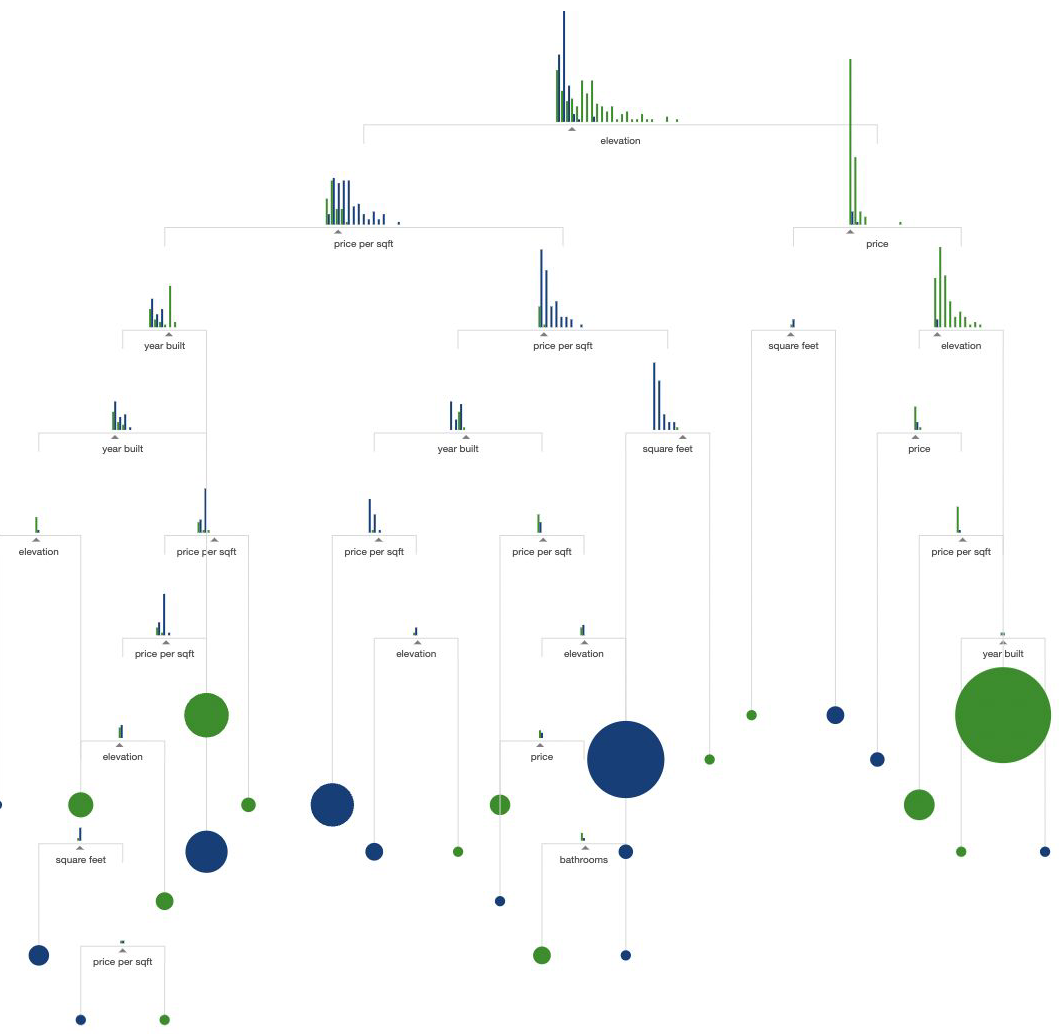
CART#
Regularisation:
pruning to avoid overfitting
Grow a full tree and then prune e.g.
max_leavesmax_depthmin_sample_size
CART - pros and cons#
| PROS | CONS |
|---|---|
| white box model - easy to interpret | not very accurate ... |
| can handle mixed data, discrete and continuous | greedy nature of constructing |
| insensitive to transformations of data... split points based on ranking | trees are unstable, small changes to the input can lead to large changes in tree structure |
| relative robust to outliers | tend to overfit (aka high variance estimators) |
Trees being unstable#
Q: Should you trust and follow a single CART?
Changes in your data can lead to different tree structure and maybe different decisions
As in investment, it is not advisable to lay all eggs in one basket

Trees being greedy and overfitting#
How to find out what to order at the restaurant?
Try everything!
… and then order what you liked best.Ask your friends to try something,
find out which they preferred more and try those maybe?
Q: Which do you find more feasible?



Wisdom of Crowds Theory#
Diversity of opinions
Independence of opinions
Decentralisation
Aggregation
Who Wants to Be a Millionaire 💸 // 📖 Wikipedia#
| Who Wants to Be a Millionaire 💸 | Wikipedia 📖 |
|---|---|
| Each person has private information. | |
| The audience members should have opinions of their own. | Wikipedians have opinions of their own. |
| Independence of opinions. | |
| There might be some small local effects. | Wikipedians often don’t know each other. |
| Decentralisation | |
| Trivia knowledge isn’t specialised. People can make educated guesses. | Wikipedia is decentralized by definition. Single-author pages require review. |
| Aggregation | |
| People chose the most popular vote: max() | Talk pages to discuss and mediate disagreements. Decisions by consensus or executive decision. Loss of independence or lack of aggregation. |
Reducing variance by aggregation#

Ensemble learning… asking for more opinions and making a judgment call#
A collection of models working together on same dataset
Mechanism:
majority voting
There are different ways to do it:
bagging (same model on different parts of the data)
boosting (seq. adjusts for importance of observations)
stacking / blending (training in parallel and combining)
Advantages:
less sensitive to overfitting
better model performance

Majority Voting - how it works#
For each observation you have different predictions from different models
You need one prediction… so you aggregate
Aggregating the different models can be done in many ways e.g. averages, mode, median
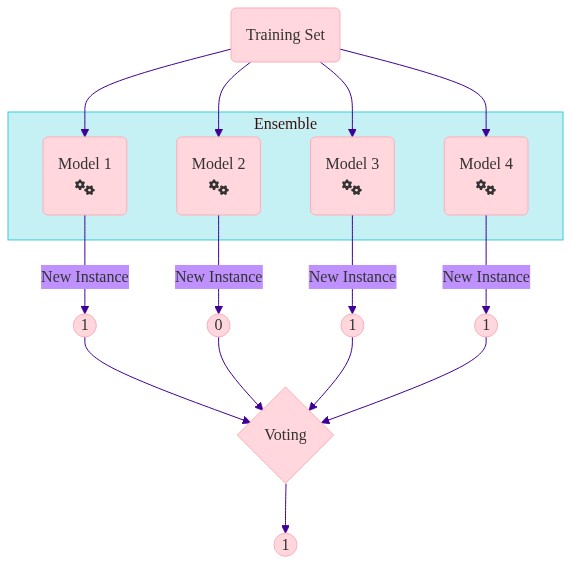
Methods based on the values of the probabilities need to return calibrated probabilities.
Majority Voting - how it works#
For each observation you have different predictions. How do you aggregate this to get one value?
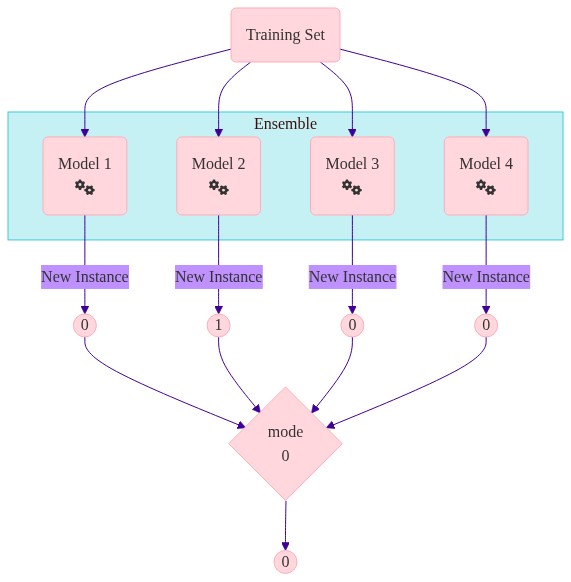
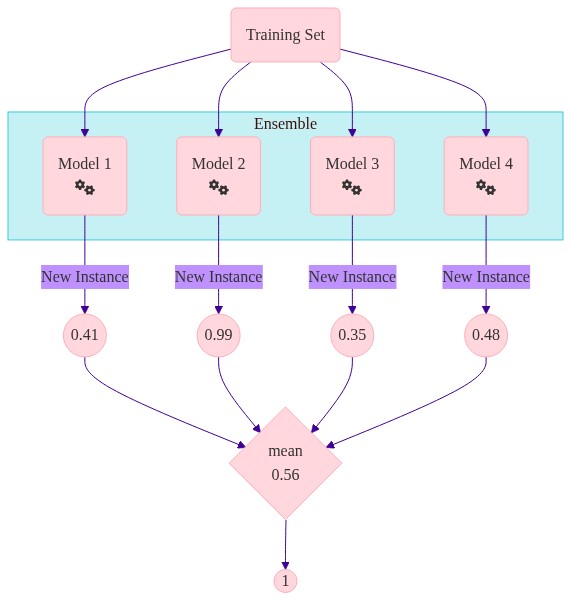
Soft voting tends to outperform hard voting.
Majority Voting - why it works#
Intuition: at observation level not all classifiers will be wrong in the same way at the same time
Prerequisites for this to work:
models need to be better than random, i.e. weak learners
you want the models to be different and that get translated in statistics to non-correlated or sufficiently independent or .. diverse
you need a sufficient amount of weak learners

A weak learner model has an average true positive rate slightly better than 50% and an average false positive rate slightly less than 50%.
Majority Voting - why it works#
What does it mean that the models are independent/ different?
If two weak learners would be correlated then a observation is likely to have same prediction by both weak learners.
Why do you think it is important?
Probability of an observation x to be misclassified by the ensemble learner is basically equivalent to it being misclassified by a majority of the weak learners.
 A weak learner is 51% right and 49% wrong
A weak learner is 51% right and 49% wrong
This can be proven by math. Feel free :D to try.. or
run 1000 coin toss experiments and aggregate.
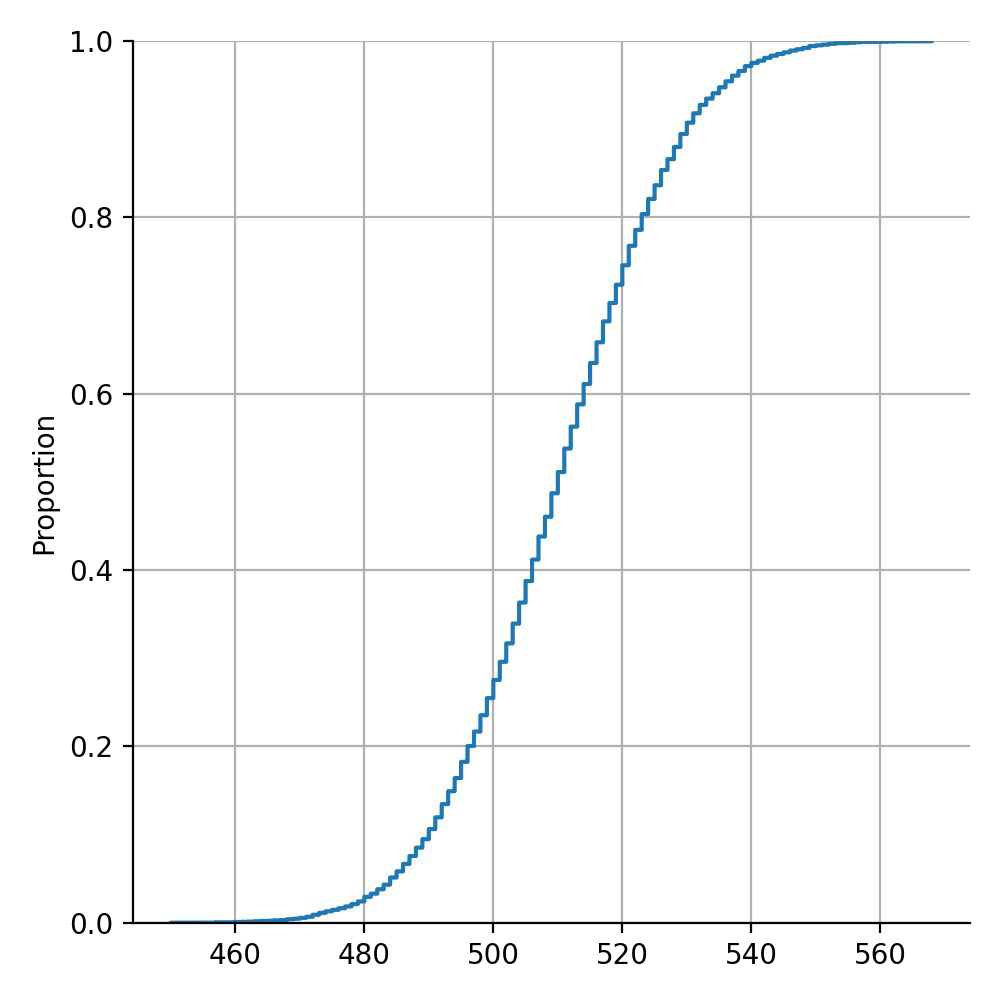
Example of weak learners#
Chances to be wrong with m = 1000 weak learners.
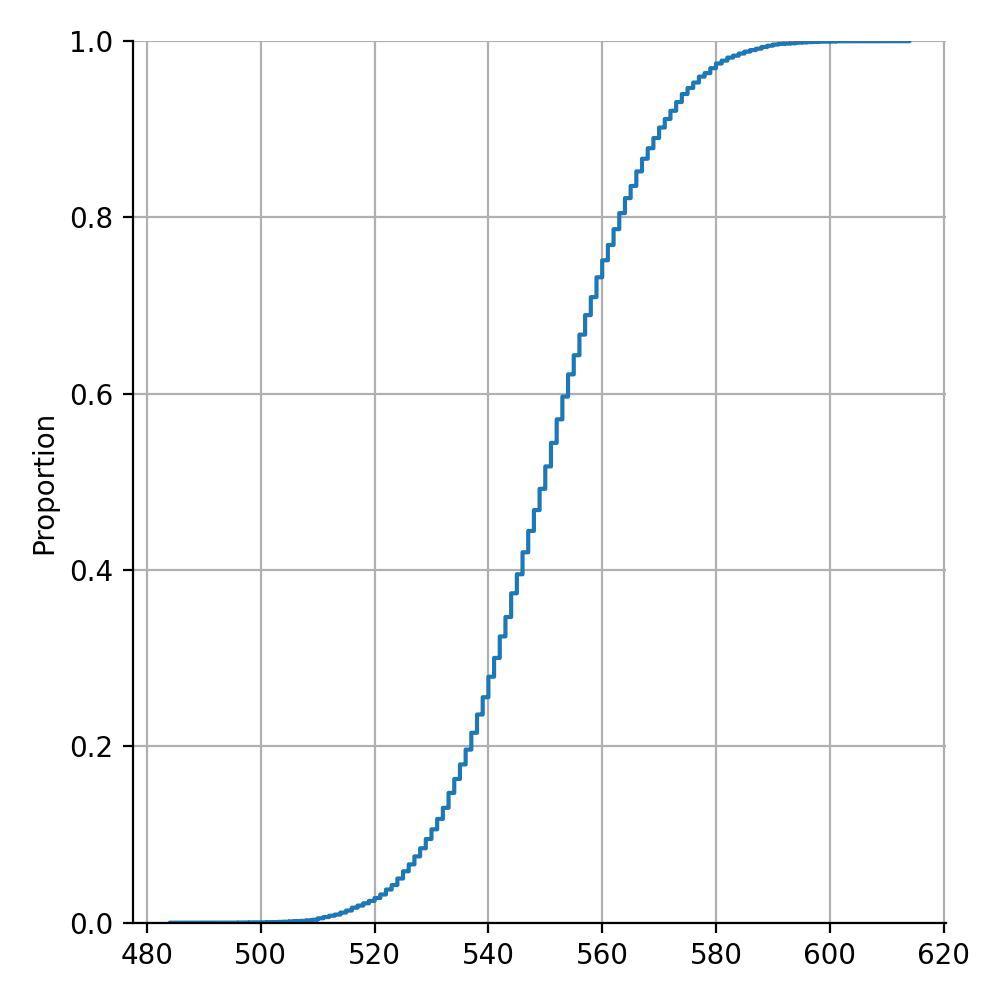
Example of weak learners#
Chances to be wrong with m = 1000 weak learners.
How does my model look as an ensemble model?#
Adaptive basis function models#
This framework covers many models: decision trees, neural networks, random forest, boosting trees and so on… basically we have m parametric basis functions.
How does the formula look like for a decision tree?
How do I produce different models with the same data?#
I. Different models#
Using different models#
Really different models, not necessarily weak models. So you could use 3 or more of different types:
decision trees
random forest
neural networks
SVMs
NBs
KNN
Ridge Classifier
…
II. Bagging#
Bagging#
Bootsprap aggregating
Training \(m\) different trees on different subsets of data chosen randomly with replacement.
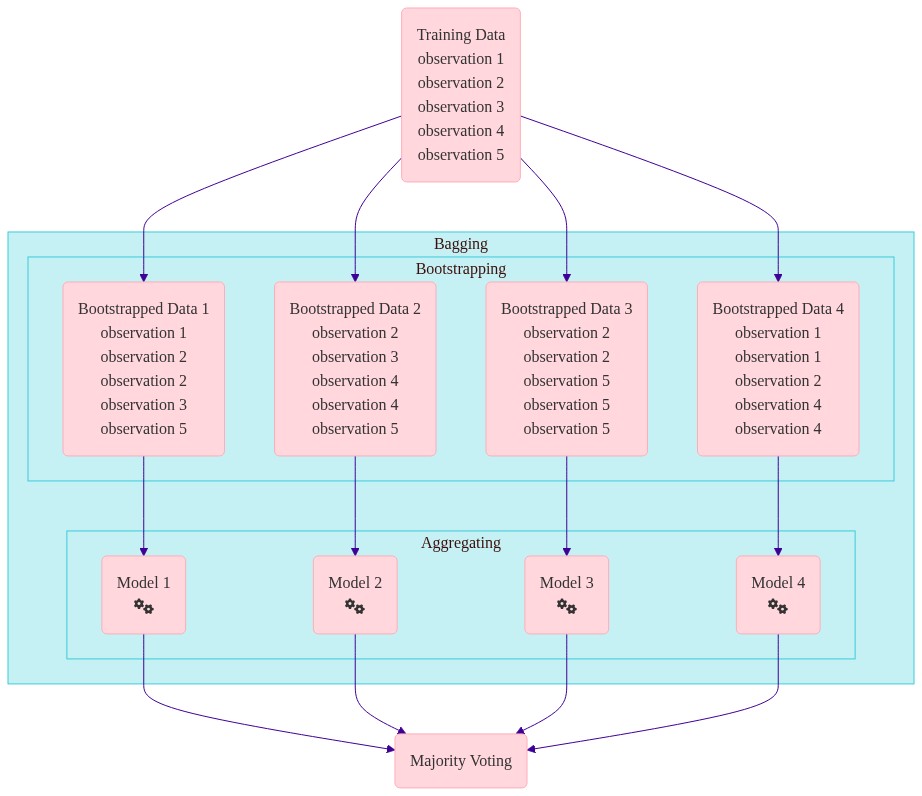
Running same learning algorithms on different subsets can result in still highly correlated predictors.
Random forest#
Random forest is a technique that tries to decorrelate the predictors
randomly chosen subset of input variables (features)
leading to different features used at each node
randomly chosen subset of data cases (observations)
leading to out of bag instances
Random forest gain in performance but lose in interpretability.
Prevents trees from relying on the same strong features
Increases diversity between trees
Reduces correlation → better ensemble performance
this is an hiperparameter max_sample
Extra-Trees - Extremely Randomized Trees#
Changing how we build the trees to introduce more variation
all the data in train is used to build each split
to get the root node or any node: searching in a subset of random features, the split is chosen randomly
random selection → Saves a lot of computational power
Accuracy vs variance#
Accuracy
Random Forest and Extra Trees outperform Decision Trees
Variance
Decision trees → high
Random Forest → medium
Extra Trees → low
References#
Machine learning a probabilistic perspective - Kevin p. Murphy