Regularization#
Part 1#
Recap on Bias-Variance Trade-Off#
Bias - Variance Trade-Off#
→ to minimize the cost we need to find a good balance between the Bias and Variance term of a model
→ we can influence bias and variance by changing the complexity of our model
Example: Underfitting vs. Overfitting#
We got data. But we don’t know the underlying Data Generating Process.
So we want to model it.
Do you see a pattern/trend?
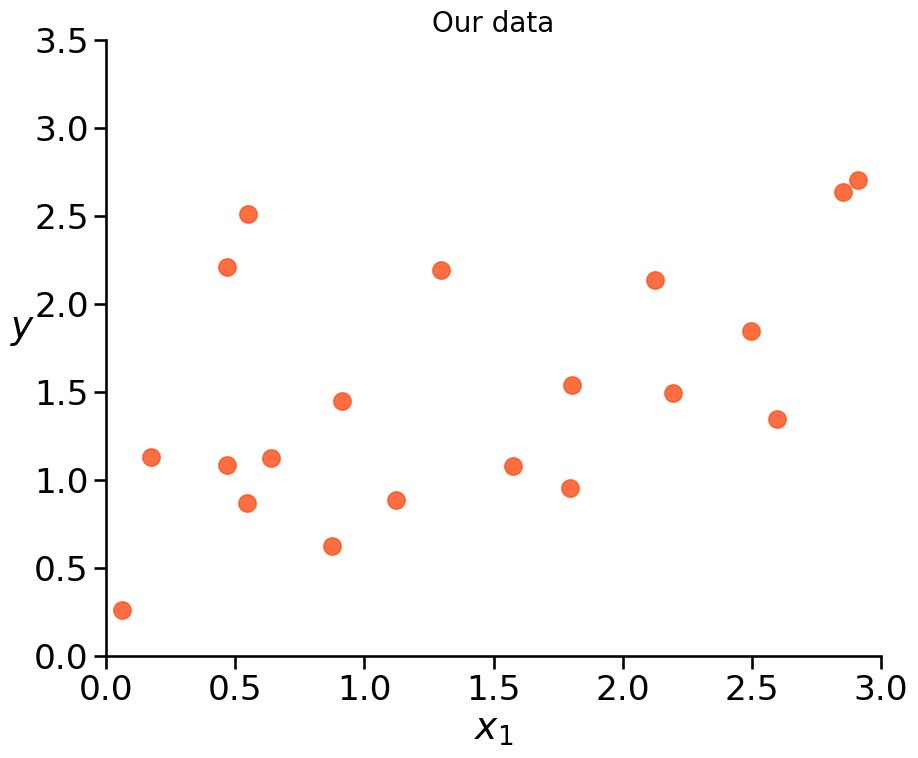
Example: Underfitting vs. Overfitting#
Which model seems best?
Which model seems to underfit the data?
Which model might overfit the data?
How to evaluate if a model is underfitting/overfitting?
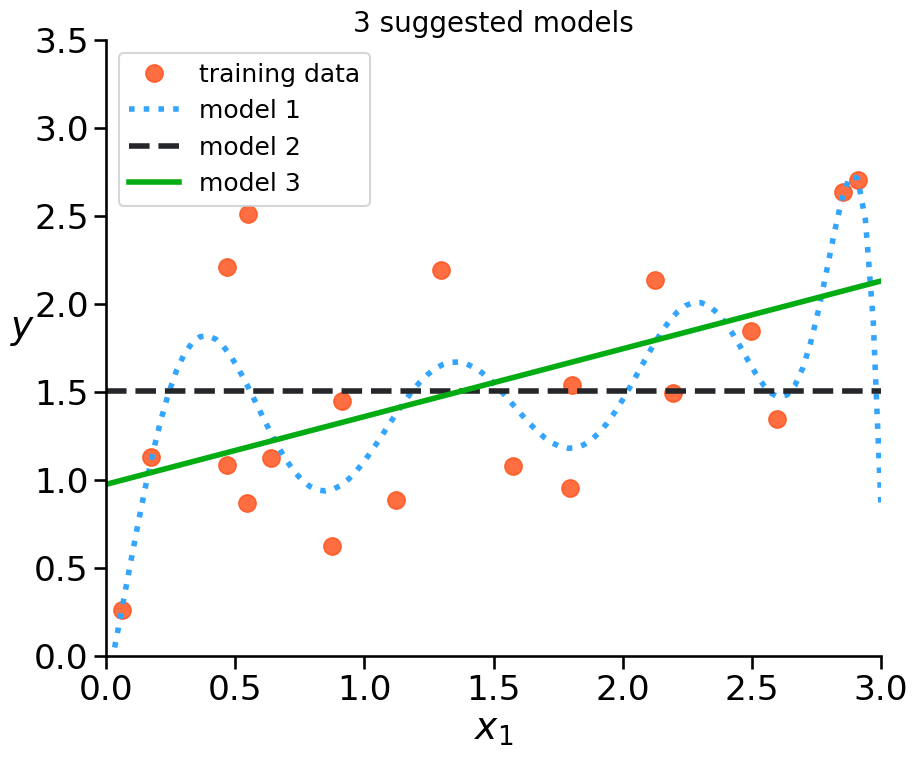
Example: Underfitting vs. Overfitting#
How to evaluate if a model is underfitting/overfitting?
we need a cost function
we need test data
we should do error analysis
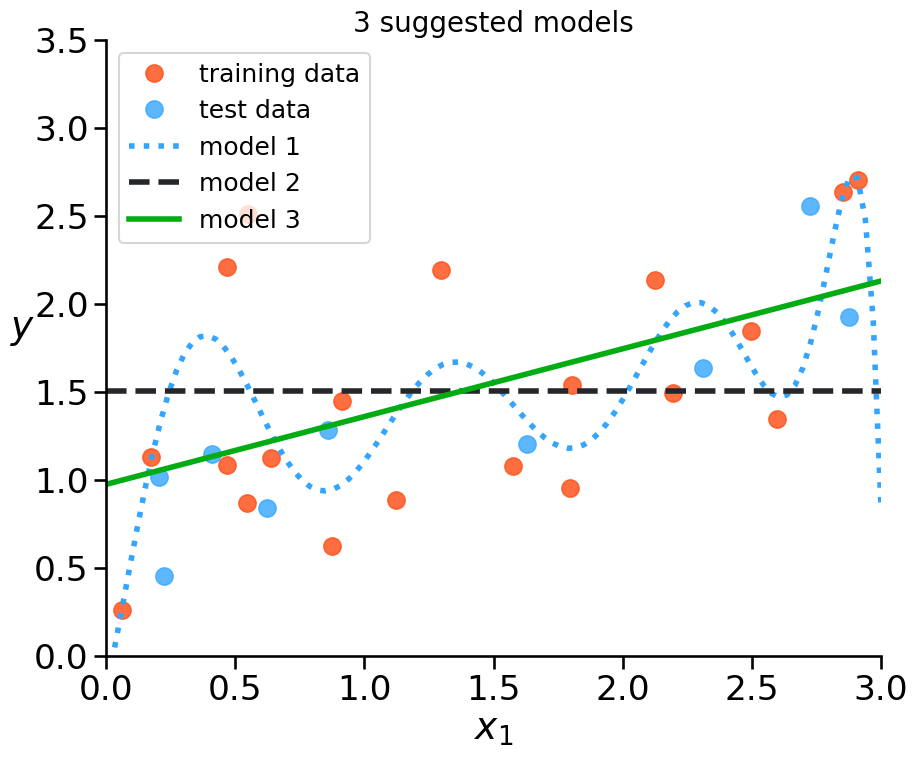
Example: Underfitting vs. Overfitting#
How to figure out if your model is overfitting?
Example: Underfitting vs. Overfitting#
How to figure out if your model is overfitting?
error on training data is low
error on test data is high
→ model memorizes the noise in the data
Example: Underfitting vs. Overfitting#
How to figure out if your model is overfitting?
error on training data is low
error on test data is high
Part 2#
A Visual Approach#
Prevent Overfitting#
If we see overfitting of our model, we could gather more data.
Prevent Overfitting#
If we see overfitting of our model, we could reduce its complexity.
HOW?
Prevent Overfitting#
If we see overfitting of our model, we could reduce its complexity.
HOW?
reduce amount of features
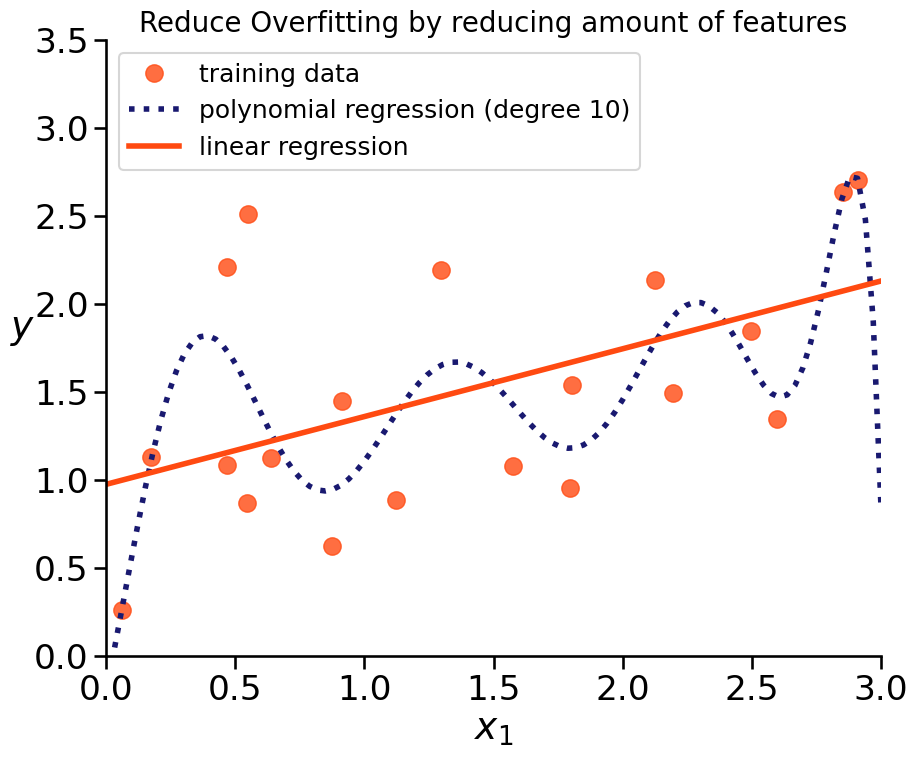
Prevent Overfitting#
If we see overfitting of our model, we could reduce its complexity.
HOW?
reduce amount of features
make the model less susceptible to data by reducing the influence of features
→ smaller coefficients
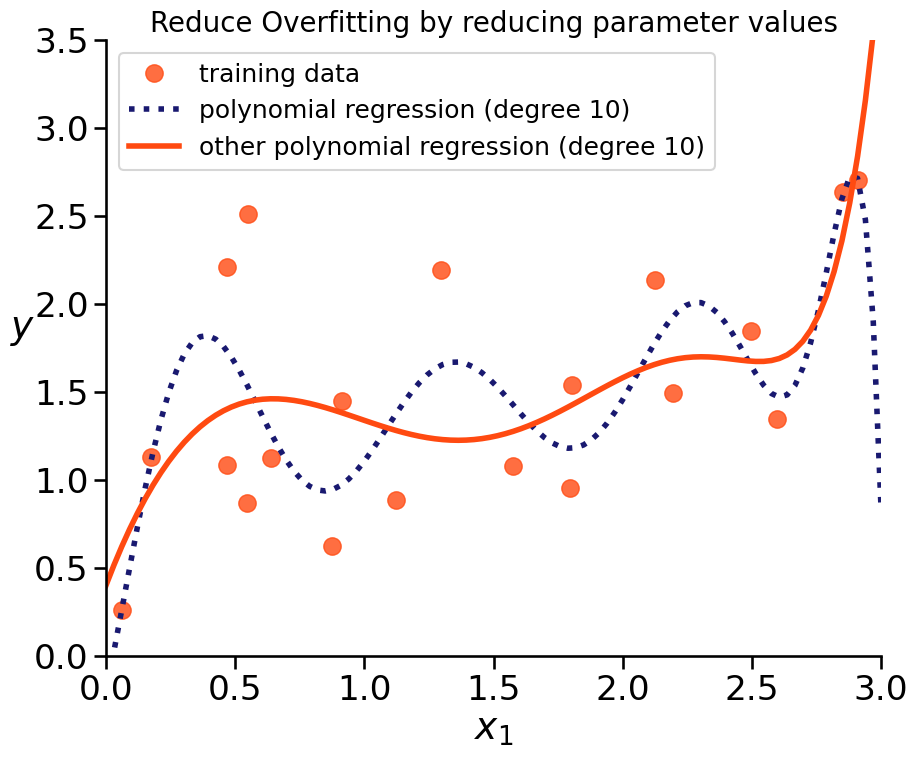
Prevent Overfitting with Regularization#
BOTH can be achieved with regularizing a model:
reduce amount of features
make the model less susceptive of data by reducing the influence of features (smaller coefficients)
Part 3#
Regularization#
Regularization#
Regularization conceptually uses a hard constraint to prevent coefficients from getting too large, at a small cost in overall accuracy. With the aim to get models that generalize better on new data.
Hard constraint#
We add a hard constraint to our cost function:
General form of the constraint:
What do we have to change to get to a form like this:
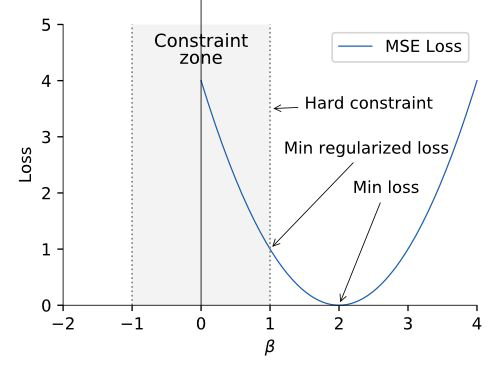
Hard constraint#
We add a hard constraint to our cost function:
The most common regularization constraints:
Hard constraint with more features#
We add a hard constraint to our cost function:
The most common regularization constraints:
Soft constraint#
We can add this constraint directly to our Loss function (t becomes alpha (or lambda))
Alpha is a hyperparameter. Before training the model we need to set it.
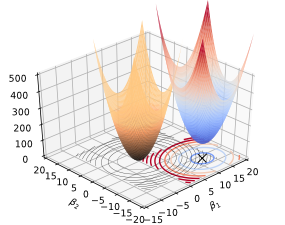
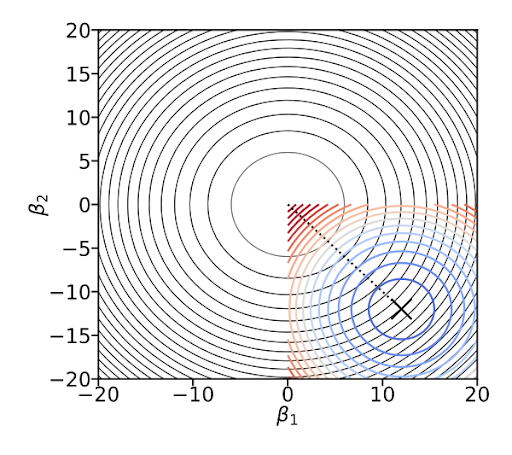
Soft constraint#
We can add this constraint directly to our Loss function (t becomes alpha (or lambda))
What happens if we set alpha to 0?
What happens if we set alpha to a very high value?
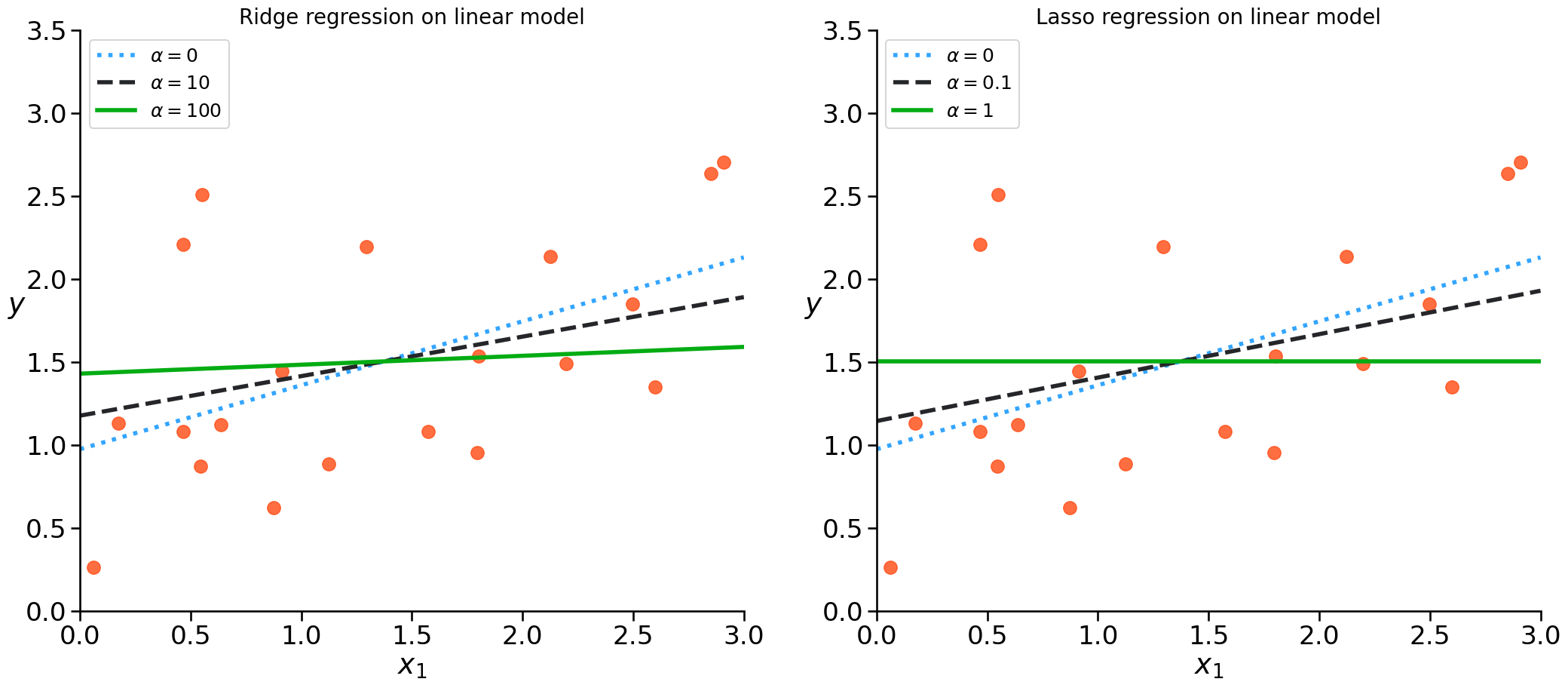
Sklearn code for regularization#
check sklearn documentation here
ridge_mod = Ridge(alpha=1.0) #adjust the alpha level
ridge_mod.fit(X, y)
ridge_mod.predict(X)
Some different alpha values#
We have to test some values for alpha and check which give us best results on unseen data
print(f'the MSE for Ridge regularization and alpha = 0.5 is:', get_mse(Ridge,X,y, polynomial=True, alpha=0.5))
print(f'the MSE for Lasso regularization and alpha = 0.5 is: ',get_mse(Lasso,X,y, polynomial=True, alpha=0.5))
the MSE for Ridge regularization and alpha = 0.5 is: 0.2957168909631701
the MSE for Lasso regularization and alpha = 0.5 is: 0.4647391677603675
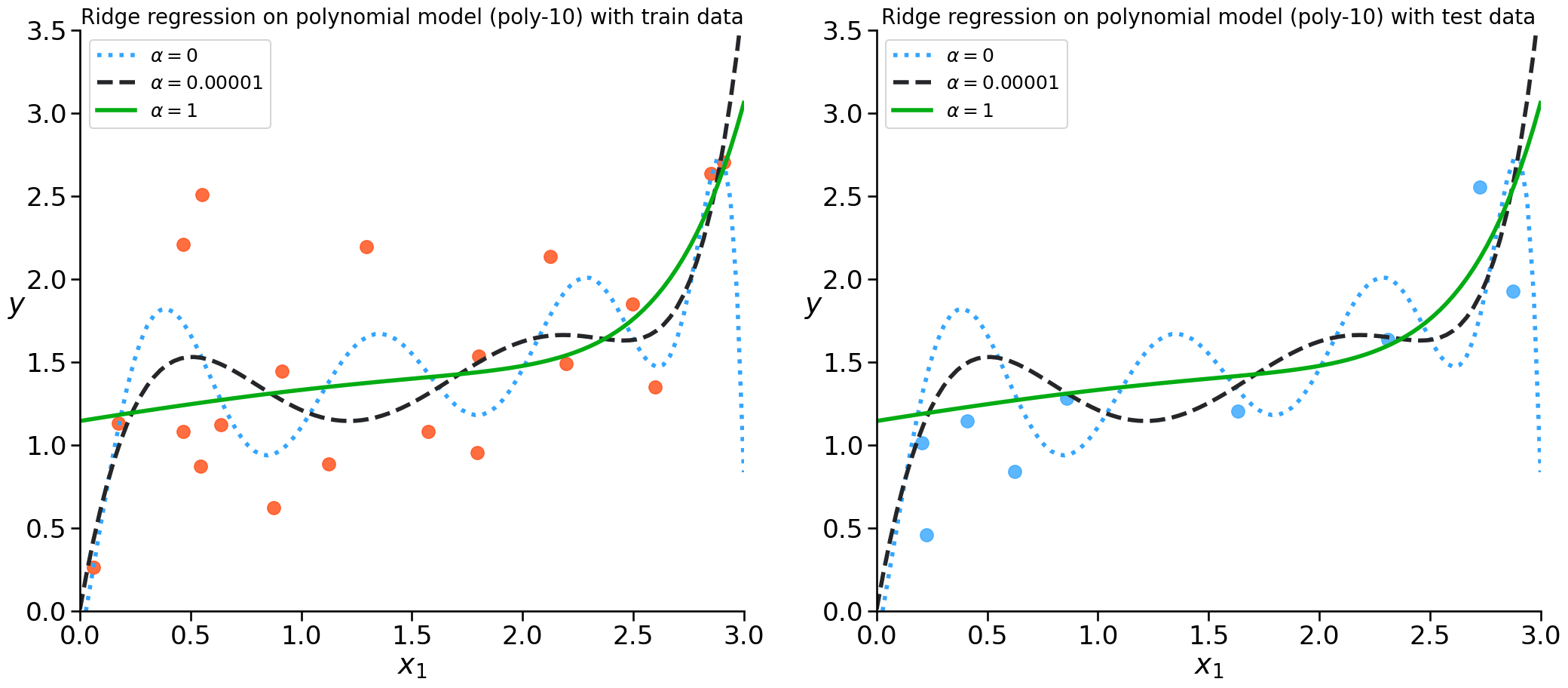
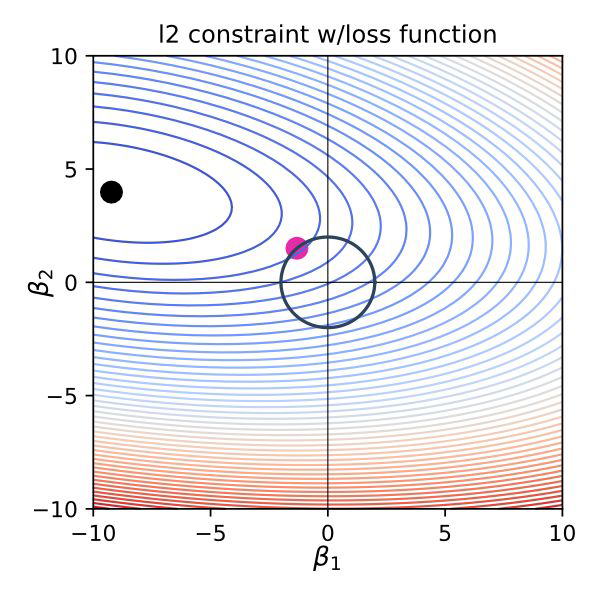
Ridge Regression#
Also called L2 Regularization / l2 norm
the regularization term forces the parameter estimates to be as small as possible - weight decay
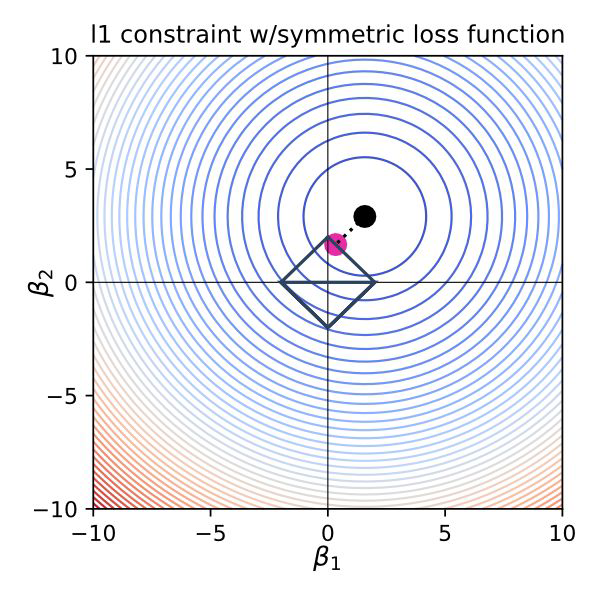
Lasso Regression#
Least Absolute Shrinkage and Selection Operator
Also called L1 Regression / l1 norm
Tends to eliminate weights = it automatically performs feature selection
Ridge vs Lasso#
Why is L1 eliminating while L2 only reducing weights?#
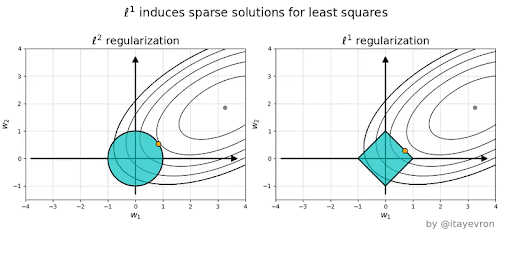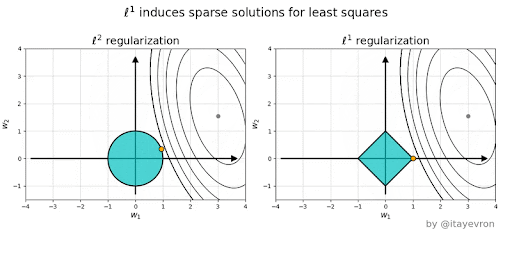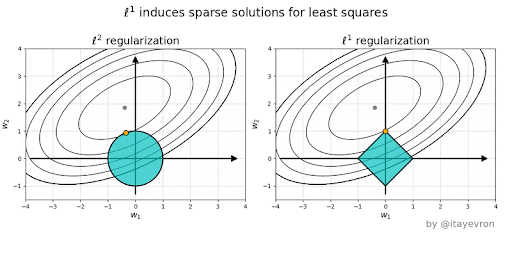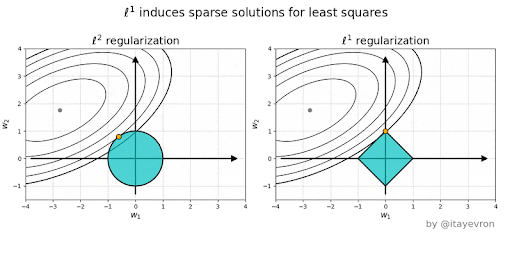
Elastic Net - Mixing Lasso and Ridge#
Regularization term is weighted average of Ridge and Lasso Regularization term
When r = 0 it is equivalent to Ridge, if r = 1 it is equivalent to Lasso Regression
Preferable to Lasso when features are highly correlated or to Ridge for high-dimensional data (more features than observations)
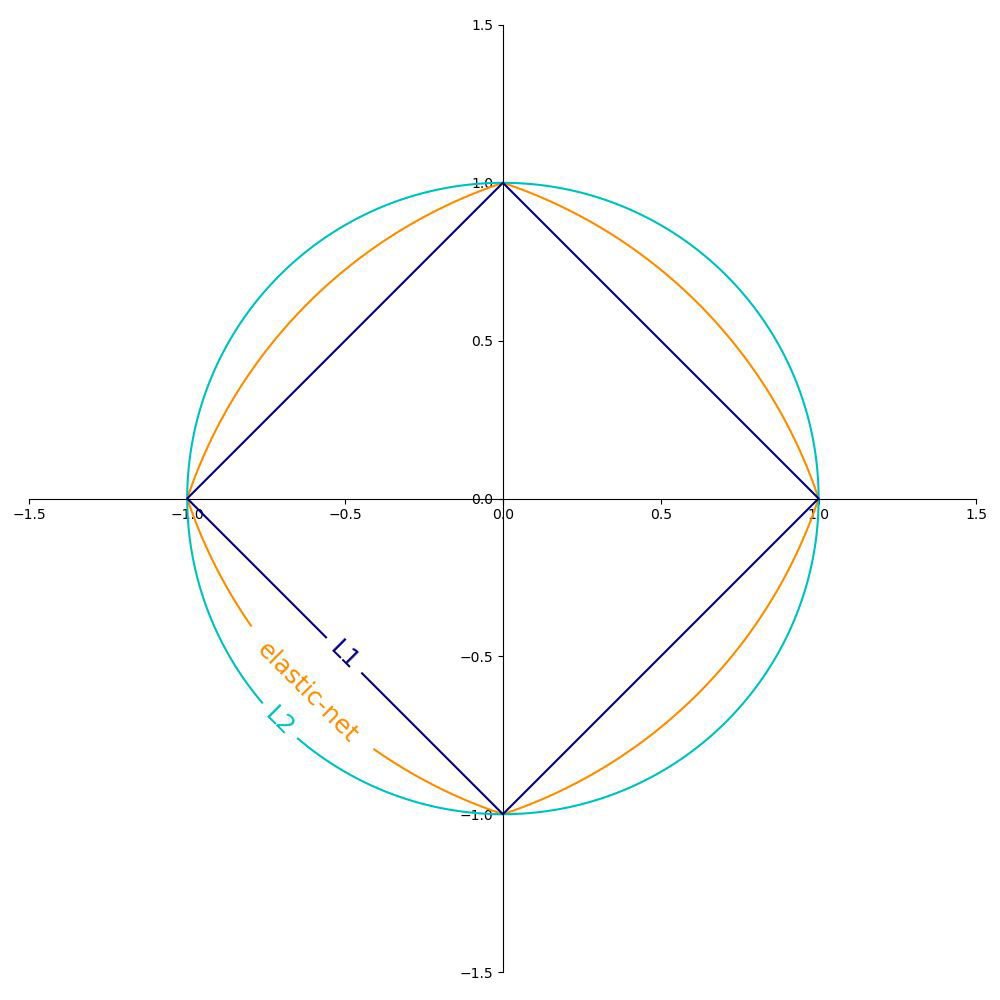
Comparison of regularization methods#
elastic net is between L1 and L2 (whatever you use as r… it will change its form more to L2 or L1
References#
Hands-on ML with scikit-learn and TensorFlow, Geron
https://medium.com/analytics-vidhya/bias-variance-tradeoff-for-dummies-9f13147ab7d0
Machine Learning - A probabilistic Perspective - Kevin P. Murphy
