Recap#
A data science project lifecycle#
CRISP-DM
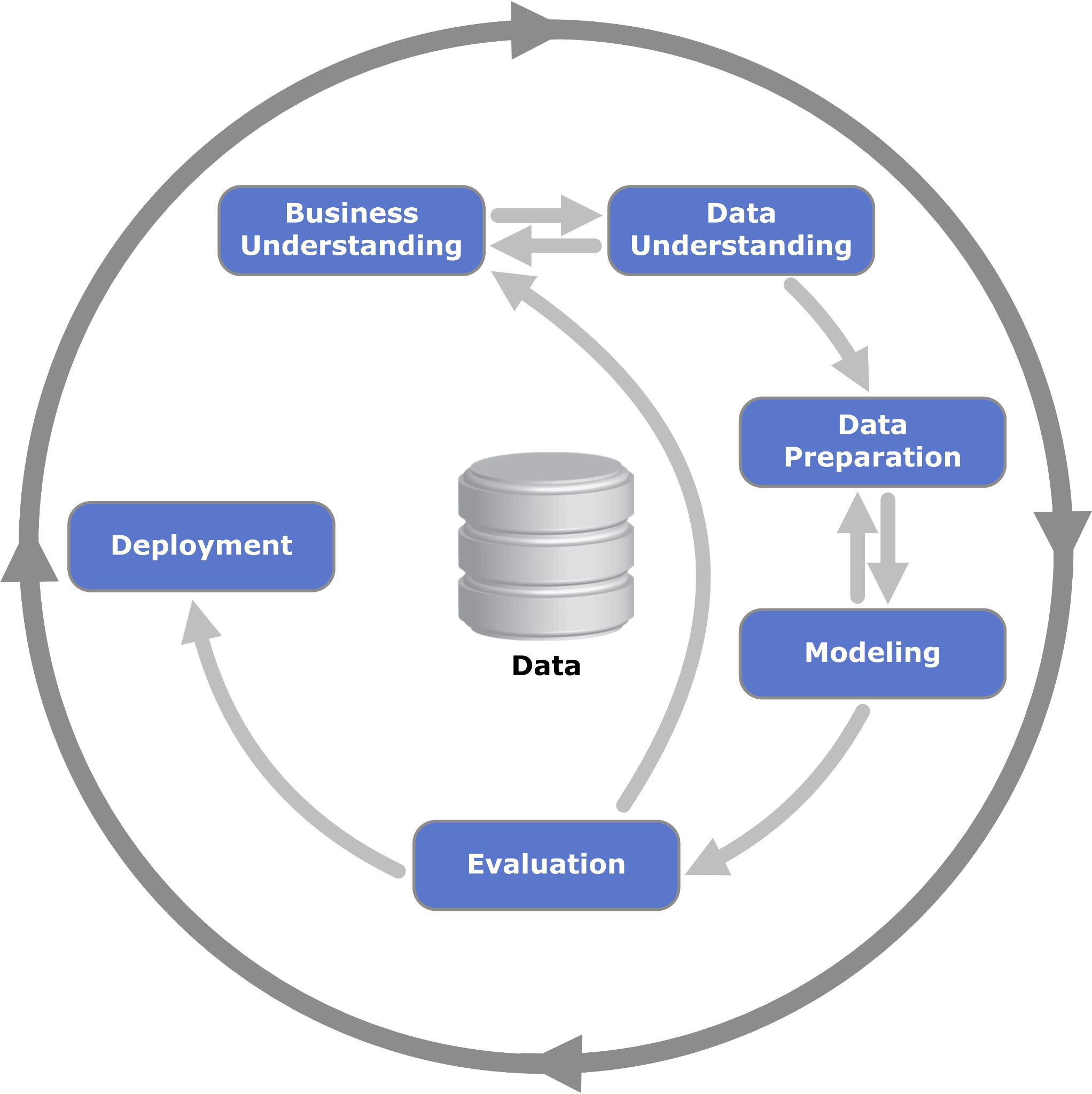
figure by Kenneth Jensen
Some things you will do for business understanding#
Identify stakeholders
Define an objective
Describe your solution
Identify how your solution ties into the client’s business processes
Identify metrics / KPIs for measuring success
Presenting results: assess risks, and potential business impact
Some things you will do for data understanding#
Data acquisition
Data cleaning
What does each column mean? Is the format correct?
Are there any columns with many missing values?
False or unexpected data, outliers
Over what time range / region do you have data?
Check for imbalances and decide on stratification
Exploratory Data Analysis (EDA)
Split your data to train/test sets and continue with your training set
Make some plots of the data distributions. Check if they are what you would expect. e.g. plot “number of ice cream bought” throughout the year - is it highest in the summer?
Some things you will do for data understanding#
Exploratory Data Analysis (EDA)
Numerical features: pairplots, scatterplots, boxplots.
Categorical features: countplot, frequency table, sunburst plot
Feature Engineering
Impute, infer, and rescale only on the training set
Add relevant features, e.g. calculate the weekday for every date in the data.
Some things you will do for modeling and evaluation#
Define your evaluation procedure
Make sure it is relevant given your business understanding
Establish a baseline. This is the simplest model you can think of. For example:
Predict that tomorrow we will sell exactly the same as today
Predict that tomorrow we will sell the average of the last year
Train an actual model, compare with baseline.
Use cross validation in training
Return to EDA and feature engineering as needed
Tune hyperparameters to improve performance
Perform error analysis as needed
Questions#
Is sklearn widely used in production in the real world (on large data / big data)?
Yes
Is Linear Regression with Polynomial Expansion (which we covered with Evgeny) often used? Expand polynomially and then scale or the other way around?
First scale, on training set, the fit a linear model
LR is commonly used in production, often with regularization
not sure specifically about polynomial expansion
Questions#
How to decide which algorithm to use? We only know small proportion of available algorithms.
Based on the data availability (labels? linear relationship?) & problem:
Regression only: Linear regression
Classification and Regression: Decision trees, KNN
Classification only: Logistic regression
Questions#
Shortly compare advantages/disadvantages of learned models.
LR: RMSE has same units as predicted variable, relationship between dependant and independent variables must be linear
Logistic: Doesn’t tolerate colinearity, can indicate feature significance
KNN: Slow at prediction, non-parametric, support non-linear solutions, few hyperparameters to tune
DT: High variability, can handle colinearity, can’t indicate significance
How do we know that our model is good enough? At what point do we stop trying to further optimise? Are there threshold values for the evaluation metrics considered as “good”?
Better than random and baseline
Questions#
Are there any rules of thumb for evaluation metrics for typical/most common business cases that are best suited for regression/classification ? Or should we try as many as possible?
Try several for the intended solution (evaluation metric should match the business case)
Consider resources, risks and objectives (time and costs, sample complexity, B-V, labeling, parametricity)
Online and Offline learning (use-case: API, freshness)
What is the best way to keep track of changes and optimisations of ML models and their respective evaluation metric?
Experimintation tracking tools!
MLflow, AIQC, Weights & Biases (WandB), Data Version Control (DVC), Excel 😇
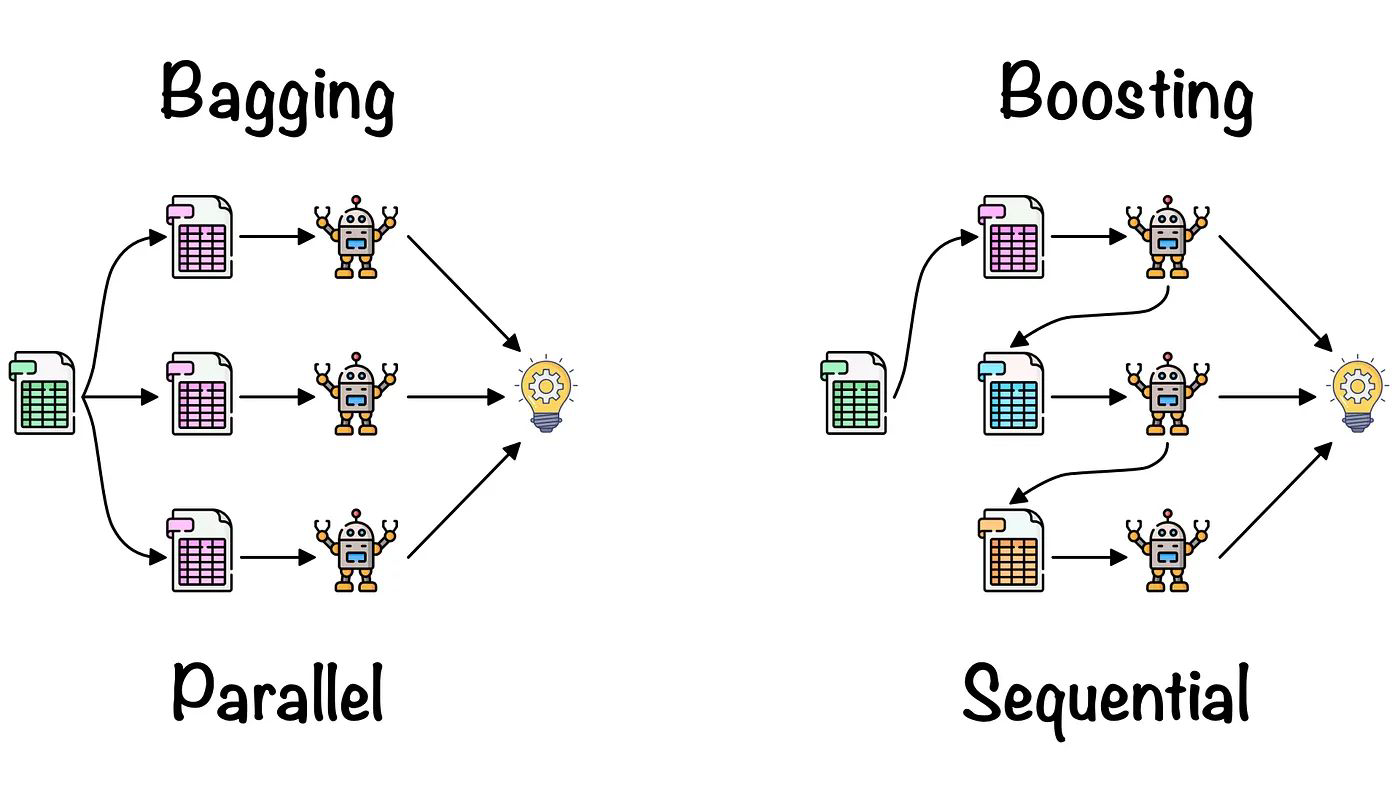
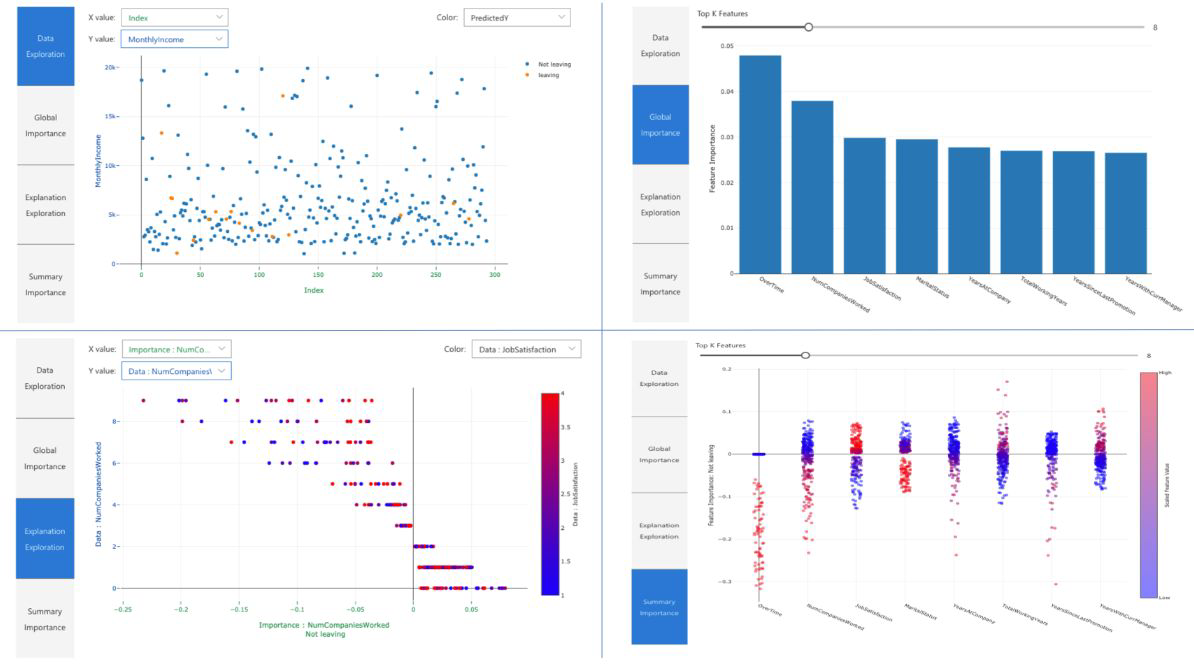
Even More Machine Learning#









A data science project lifecycle#
CRISP-DM
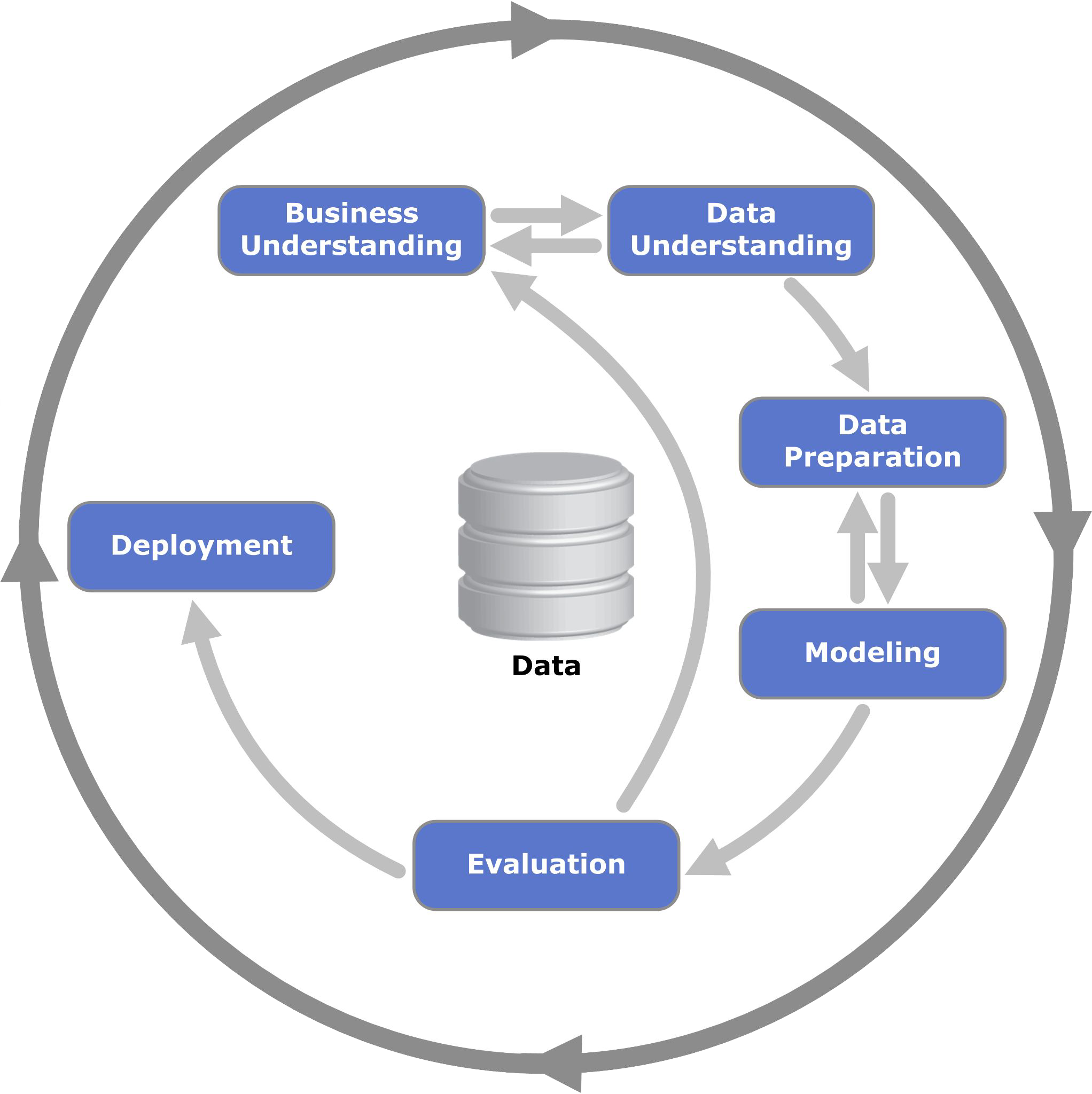
figure by Kenneth Jensen
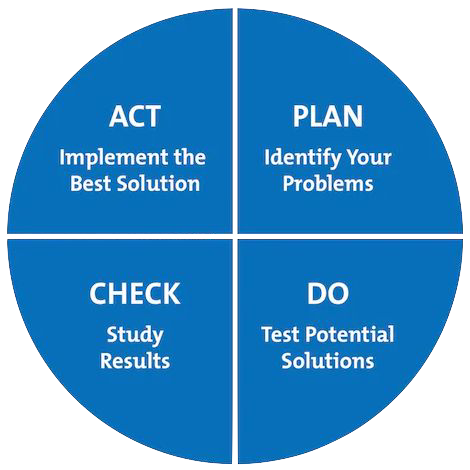
Project Management#
PDCA
Communication and feedback
Collaboration
Questions#
On which models to focus on for practice/interviews.
That’s really hard to say. It depends on the domain. I think RF and XGBoost are super common in solutions I’ve seen. But if you want to work in NLP, or image recognition, better focus on ANN and recent examples from those doamin.
list/resources for typical methodical interview questions
Every hiring manager and team have their own preferences for screening, and current needs in the DS/ML team
There are folks who collect resources in github but that usually leads to a huge number of questions - and I wouldn’t expect anyone to know EVERYTHING
It’s good practice to:
ask in advance if there are specific topics you could review to be better prepared
know how to answer questions related to your case study/take home solution. If you used RF, expect to be able to answer questions about RF.